HL7 Programming using .NET and NHAPI - Message Validation
Introduction
This is part of my HL7 article series. Before we get started on this tutorial, have a quick look at my earlier article titled “A Very Short Introduction to the HL7 2.x Standard”. One of my earlier tutorials in this series titled "HL7 Programming using .NET - A Short Tutorial" also gave you a foundational understanding of HL7 2.x message transmission, reception and message acknowledgement. Other articles in this series on HL7 programminng using .NET included looking at how to create, transmit, parse, terse messages as well as how to handle binary data during HL7 2.x messaging using the NHAPI HL7 library (a port of the original Java-based HAPI framework which I covered in my previous tutorials). Although these capabilities are all very important, one capability that is highly desired in any message communication is whether the messages are correctly understood by both parties involved in the message exchange. Two terms namely semantic interoperability and technical interoperability are often discussed in this context. Let us quickly review these two terms before we go any further.
Technical interoperability refers to ability to communicate at a "system level" which ensures that a specific information package can simply be delivered from one system to another. However, this alone is not sufficient in many situations, especially in healthcare where the parties strive for a "higher level" of communication of data. Semantic interoperability is a term used to refer to the idea that any information that is exchanged between the parties is actually "understood" by one another. This ensures that no erroneous misinterpretation of the data arises. In healthcare settings, errors in interpretation of data could even mean life or death for the patients involved.
Semantic interoperability is often the most desired (and mostly elusive) goal of any healthcare message exchange. Achieving this goal is very hard, and this is especially true in the HL7 2.x standard which has a lot of optionality built-in. This optionality poses many challenges since a lot of data is either not sent when it should be, or the data is sent in a different part of the message than where the data is expected by the receiving party. Additional features (including Z-segments which we looked at in a previous tutorial) can cause even more opportunities for confusion as the two systems cannot be certain what to expect when messages are communicated between one another unless the specifications are drawn out and agreed upon well in advance. To solve these challenges a number of approaches are often utilized within HL7 message processing systems to ensure that any message interfaces conform to strict specifications that are agreed upon by the various parties involved and are correctly validated during any exchange of message information between these parties. We will explore how some of these can be achieved using NHAPI in this tutorial.
Tools for Tutorial
- .NET Framework 4.5 or higher
- A .NET IDE or Editor such as Visual Studio IDE or Visual Studio Code (even a text editor should suffice)
- NHAPI GitHub page is located here
- Install NHAPI Nuget Package using NuGet Package Manager
- NHAPI Tools GitHub page is located here
- Install NHAPI Tools Nuget Package using NuGet Package Manager
- Download HAPI Test Panel from here
- JDK 1.4 SDK or higher (this may be required to run HAPI Test Panel)
- You can also find all the code demonstrated in this tutorial on GitHub here
Overview of HL7 Message Validation Mechanisms in NHAPI
Compared to the original HAPI HL7 toolkit for Java, NHAPI offer only some basic validation mechanisms that we will cover in this tutorial. However, it does offer an extensible design which should allow anyone to build more advanced message validation mechanisms if/when required. In this tutorial, I will cover how this validation framework works both from a theoretical perspective as well as demonstrate how these features work by using some short code illustrations. I will also describe how we can extend this validation framework to support more complex requirements if needed. In the next tutorial in this series, I will cover another framework called NHAPI Tools that offers more advanced capabilities that are built on top of this flexible design. Let us proceed.
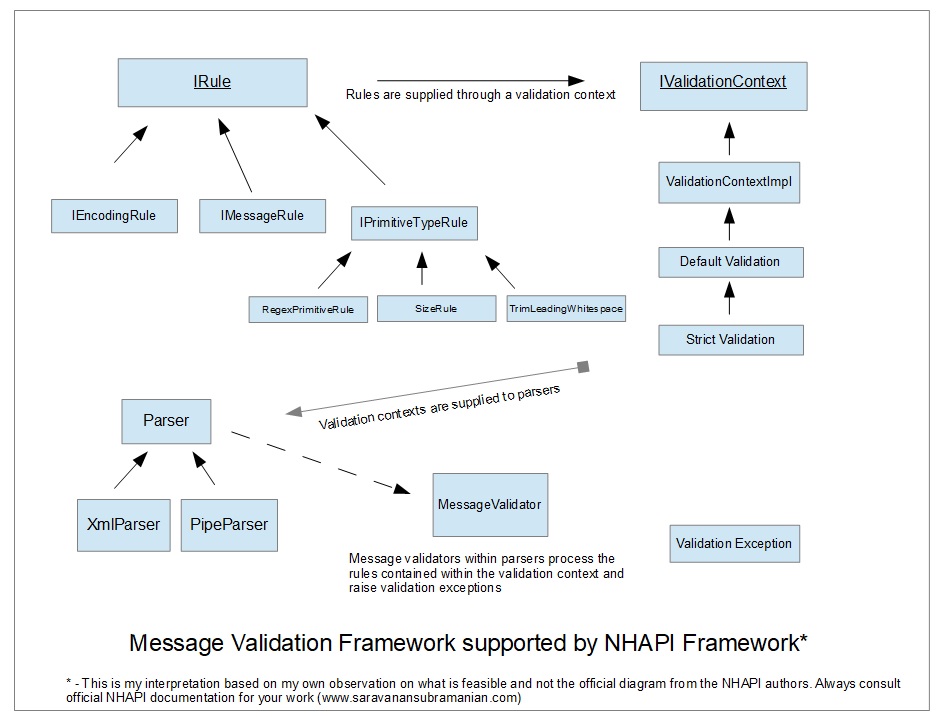
To help you see the big picture of what is going on under the covers, I have created a diagram that should help provide a breakdown of the various actors involved in the validation aspect of this framework. As you can see in the illustration above, NHAPI parsers operate under a validation context which supply various types of rules to validate HL7 message data. These rules can operate on any "level" of the HL7 message such as overall message, segments, fields, sub-components, etc. Rules can be specified to validate aspects such as size, presence and range/boundary parameters of content within the message payload. This validation context including the rules is then passed into NHAPI parsers during instantiation. A message validator contained within the parser operates on this validation context by iterating through all the rules supplied and applies them on the message payload that is being processed at any given time. If any of these rules are not met, the message validator will raise validation exceptions which can be retrieved easily.
What you can do with these rules is left only to your imagination. These rules can not only be used to perform checks but can also be used to alter the message content when required. For instance, rules can be specified to trim any whitespace in message data if necessary. I would recommend that you review the source code of the NHAPI framework for examples of various pre-built rules that you can extend or emulate for your own requirements as needed. NHAPI offers two concrete validation contexts out of the box for use during HL7 message parsing operations. These are Default Validation Context and Strict Validation Context. I will review their capabilities as well as demonstrate how to use them below using small code examples that should hopefully easy to follow even for a total beginner.
“If you only read the books that everyone else is reading, you can only think what everyone else is thinking.” ~ Haruki Murakami
Default Message Validation
The DefaultValidation class is one of the built-in validation context classes that is provided by the NHAPI framework. It overrides the ValidationContextImpl abstract class which in turn implements the IValidationContext interface. The DefaultValidation class provides some basic message validation rules such as the following:
- Trim any whitespace around "FT", "ST" and "TX" data type fields contained in the HL7 message
- Any "ID" and "IS" data type fields in the message cannot exceed a 200 character limit
- "FT" data type fields in the message cannot exceed a 65536 character limit
In the code example below, I demonstrate how to the use DefaultValidation class through an easy to understand example where I intentionally set the EVN-4 (event reason code) field to be greater than 200 characters in length. Since this field is a "IS" data type, the message validation should fail during parsing operation as it fails the rule that any "IS" data type should not exceed 200 characters in length.
private static void DemonstrateDefaultValidationInNhapi()
{
LogToDebugConsole("*Demonstration of default validation of a bad HL7 message*");
//We are going to set the value in EVN-4 (Event Reason Code - 'IS' data type field)
//to being longer than 200 characters. This should trigger an exception as part of
//the default validation rules enabled in the NHAPI parser
var eventReasonCode = "";
for (var i = 0; i < 40; i++)
{
eventReasonCode += "RANDOMTEXT";
}
var adtMessageWithInvalidEvn4Field =
"MSH|^~\\&|SENDING_APPLICATION|SENDING_FACILITY|RECEIVING_APPLICATION|RECEIVING_FACILITY|" +
"20110613083617||ADT^A01|2323232223232|P|2.3||||\r" +
"EVN|A01|20110613083617||" + eventReasonCode + "|\r" +
"PID|1||135769||MOUSE^MICKEY^||19281118|M|||123 Main St.^^Lake Buena Vista^FL^32830|" +
"|(407)939-1289^^^[email protected]|||||1719|99999999||||||||||||||||||||\r" +
"PV1|1|O|||||^^^^^^^^|^^^^^^^^";
//make the parser use 'DefaultValidation'
//You don't have to specify it normally as it is the default
var parser = new PipeParser { ValidationContext = new DefaultValidation() };
try
{
parser.Parse(adtMessageWithInvalidEvn4Field);
}
catch (Exception e)
{
//An exception should be shown here as the EVN-4 ('IS' data type field)
//has a length greater than 200 characters
//in real-life, do something about this exception
LogToDebugConsole("Message failed during parsing:" + e.Message);
}
}The results of running the parser with the default validation context enabled should result in the console output that is shown below. The parser throws a validation exception stating that EVN-4 cannot exceed the 200 character size limit.
*Demonstration of default validation of a bad HL7 message*
Message failed during parsing:Failed validation rule: Maxumim size <= 200 characters: Segment: EVN (rep 0) Field #4
“A classic is a book that has never finished saying what it has to say.” ~ Italo Calvino
Strict Message Validation
NHAPI provides another built-in validation context class called StrictValidation which simply extends the DefaultValidation class that we saw earlier. This validation context class simply adds these additional rules during HL7 message validation:
- "SI" data type fields in the HL7 message should contain non-negative integers
- "NM" data type fields in the HL7 message should contain numbers and decimals
- Date and time formats validation for any "DT","TM","DTM" and "TSComponentOne" fields
I will demonstrate how to the use StrictValidation class through another easy to understand example where I intentionally set the PID-1 (Patient ID) to a negative number. The message validation should fail during parsing operation as it fails the rule that any field of the "SI" data type (PID-1 is one such example) cannot be negative number.
private static void DemonstrateStrictValidationInNhapi()
{
LogToDebugConsole("*Demonstration of strict validation of a bad HL7 message*");
//We are going to set the value in PID-1 (Set ID – Patient ID - 'SI' data type field) to be a negative number
//This should trigger an exception as part of the strict validation rules enabled in the NHAPI parser
var adtMessageWithInvalidPid1Field =
"MSH|^~\\&|SENDING_APPLICATION|SENDING_FACILITY|" +
"RECEIVING_APPLICATION|RECEIVING_FACILITY|" +
"20110613083617||ADT^A01|2323232223232|P|2.3||||\r" +
"EVN|A01|20110613083617|||\r" +
"PID|-1||135769||MOUSE^MICKEY^||19281118|M|||" +
"123 Main St.^^Lake Buena Vista^FL^32830||(407)939-1289^^^[email protected]" +
"|||||1719|99999999||||||||||||||||||||\r" +
"PV1|1|O|||||^^^^^^^^|^^^^^^^^";
//make the parser use 'StrictValidation'
var parser = new PipeParser { ValidationContext = new StrictValidation() };
try
{
parser.Parse(adtMessageWithInvalidPid1Field);
}
catch (Exception e)
{
//An exception should be shown here as PID-1 cannot be a negative number
//in real-life, do something about this exception
LogToDebugConsole("Demonstration of Strict Validation: Message failed during parsing:" + e.Message);
}
}The results of running the parser with the strict validation context enabled should result in the console output that is shown below. The parser throws a validation exception stating that PID-1 cannot contain any negative numbers.
*Demonstration of strict validation of a bad HL7 message*
Message failed during parsing:Failed validation rule: Matches the regular expression ^\d*$
Reason: SI Fields should contain non-negative integers: Segment: PID (rep 0) Field #1
Custom Message Validation
Using the flexibility provided by the NHAPI validation framework, we can extend the behaviour by creating our own custom validation contexts which can be injected into the HL7 parsers provided by this toolkit. In the example below, I am going to create a custom message rule which will ensure that all EVN message segments always contain the EVN-4 (event reason code) field. I will then override the NHAPI provided validation context class and extend its behaviour by adding this additional rule to process during any message parsing operation involving this parser. The code illustrations below show the rule class, the custom validation context class as well as how these classes are ultimately combined to achieve the desired result.
using System;
using NHapi.Base.Model;
using NHapi.Base.Util;
using NHapi.Base.validation;
namespace NHapiParserBasicMessageValidationDemo
{
public class Evn4MustBeSuppliedRule : IMessageRule
{
public virtual string Description => "EVN-4 must be supplied";
public virtual string SectionReference => String.Empty;
public ValidationException[] test(IMessage msg)
{
var validationResults = new ValidationException[0];
var terser = new Terser(msg);
var value = terser.Get("EVN-4");
if (string.IsNullOrEmpty(value))
{
validationResults = new ValidationException[1] { new ValidationException(Description) };
}
return validationResults;
}
}
}The code below shows how a custom message validation context can be constructed. You can inject any number and type of rules here to address your interface requirements. Here, I am injecting a rule into the context that stipulates that EVN-4 field is mandatory.
using NHapi.Base.validation.impl;
namespace NHapiParserBasicMessageValidationDemo
{
internal sealed class OurCustomMessageValidation : StrictValidation
{
public OurCustomMessageValidation()
{
var evn4MustBeSupplied = new Evn4MustBeSuppliedRule();
MessageRuleBindings.Add(new RuleBinding("*", "*", evn4MustBeSupplied));
}
}
}The code shown below illustrates the use of the custom validation context that is passed into the pipe parser that is used to process the HL7 message. The custom validation helps inject the rule that ensures that EVN-4 field is supplied. The message validator of the parser will then process this new rule against the content of the parsed message and will throw a validation exception if the rule condition was not met.
private static void DemonstrateCustomValidationUsingNhapi()
{
LogToDebugConsole("*Demonstration of custom validation of a HL7 message*");
//We are going to specify a message rule that EVN-4 (Event Reason Code) field is mandatory
//We do not have any data for the EVN-4 field here in order to trigger the validation exception
var adtMessageWithMissingEvn4Field =
"MSH|^~\\&|SENDING_APPLICATION|SENDING_FACILITY|RECEIVING_APPLICATION|RECEIVING_FACILITY|" +
"20110613083617||ADT^A01|2323232223232|P|2.3||||\r" +
"EVN|A01|20110613083617|||\r" +
"PID|1||135769||MOUSE^MICKEY^||19281118|M|||123 Main St.^^Lake Buena Vista^FL^32830|" +
"|(407)939-1289^^^[email protected]|||||1719|99999999||||||||||||||||||||\r" +
"PV1|1|O|||||^^^^^^^^|^^^^^^^^";
;
//make the parser use our custom validation context class
var parser = new PipeParser {ValidationContext = new OurCustomMessageValidation()};
try
{
parser.Parse(adtMessageWithMissingEvn4Field);
}
catch (Exception e)
{
//An exception should be shown here as event reason code (EVN-4) was not supplied
//in real-life, do something about this exception
if (e.InnerException != null)
LogToDebugConsole("Demonstration of Custom Validation: Message failed during parsing:" +
e.InnerException.Message);
}
}The output of running this validation shows the validation exception that is thrown by the HAPI pipe parser when processing the HL7 message that did not contain any data within the EVN-4 field.
*Demonstration of custom validation of a HL7 message*
Message failed during parsing:EVN-4 must be supplied
Conclusion
My goal is this tutorial was to provide you an overview of the design and the various features available within the NHAPI framework to help address HL7 message validation functionality. Message validation is a very important aspect of message processing, and is required to ensure that HL7 message data conforms to various rules as specified by the overall message interface design. We looked at various actors such as classes and interfaces that are present in the NHAPI validation framework, and also looked at how to combine these actors to perform HL7 message validation using short and focused code examples. Although NHAPI framework offers a very flexible and extensible design when it comes to validation, there are still many gaps in the validation mechanisms that need to be addressed through other means if you wanted to ensure maximum interoperability and testability of your message exchange interfaces. In the next tutorial, I will show you another framework called NHAPI Tools that builds on the NHAPI framework and provides many additional validation features for use during message processing. See you then!
* - Sometimes, I use a new term that I came up with myself as there was either no formal definition of a concept in the official documentation, or because I feel that the concept is better explained using this new terminology. When in doubt, always consult the official NHAPI and HL7 documentation for final reference.